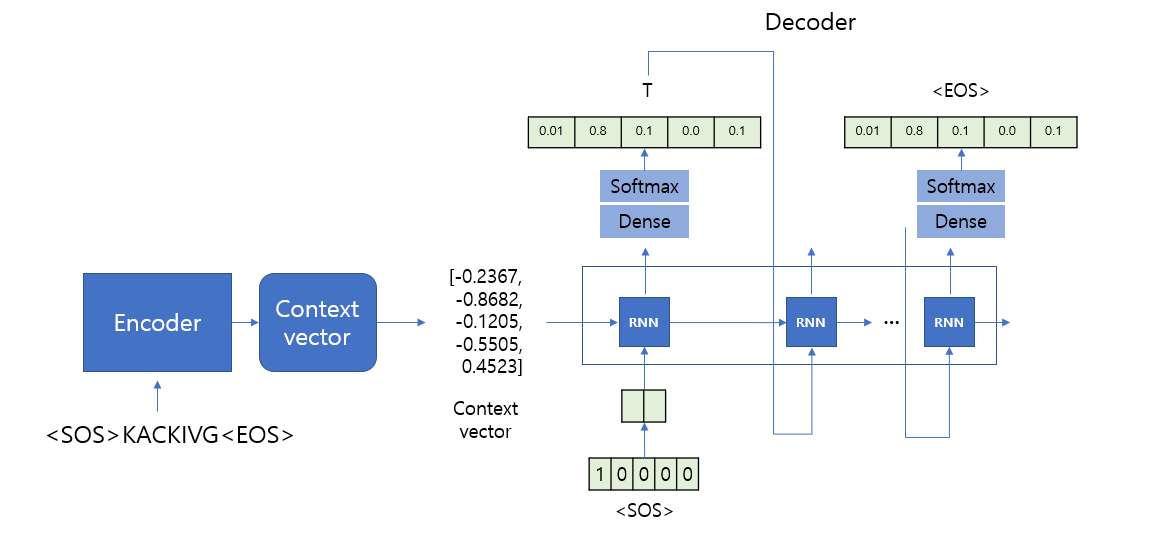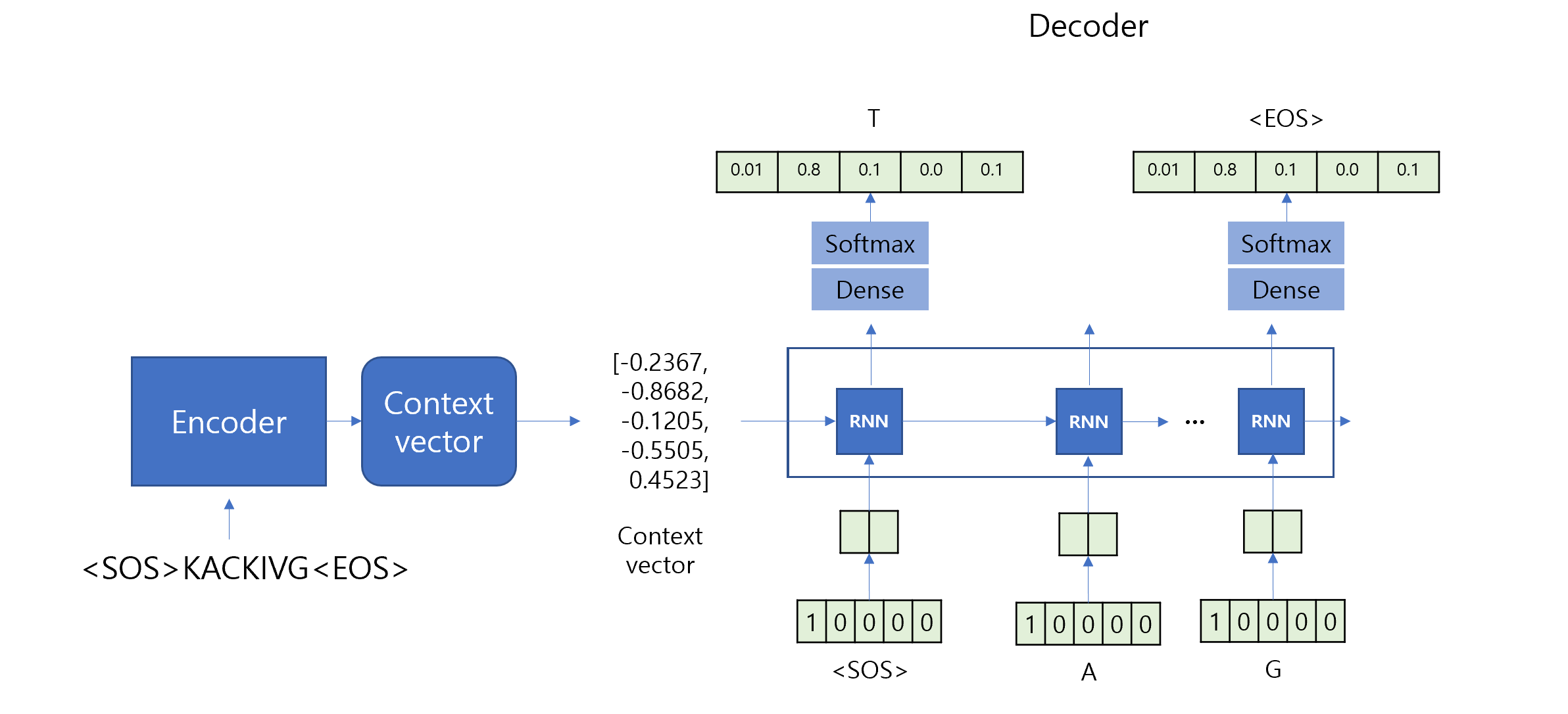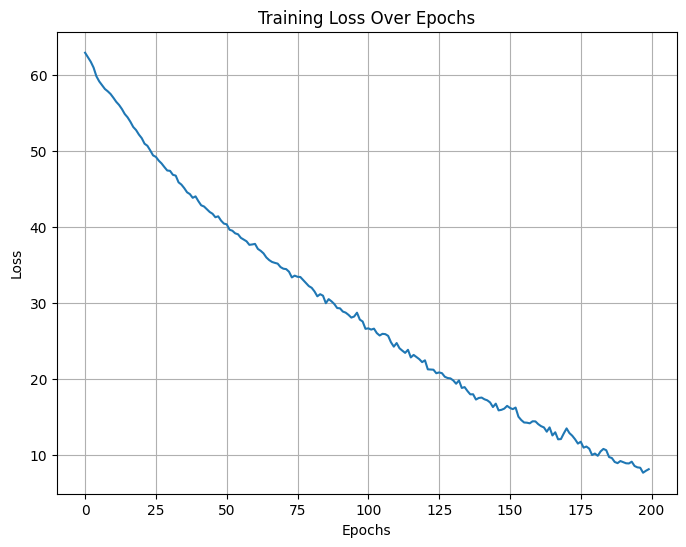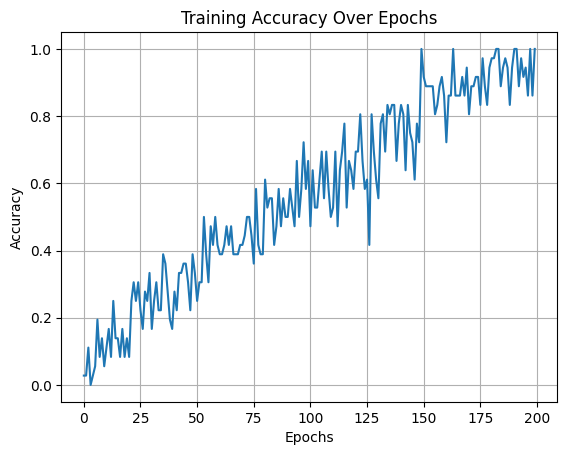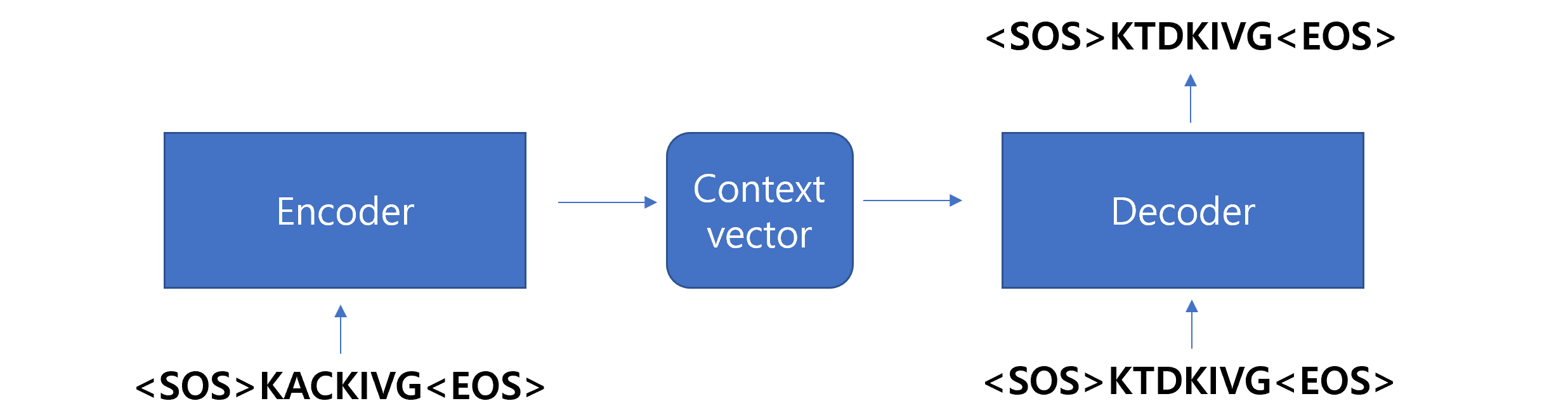
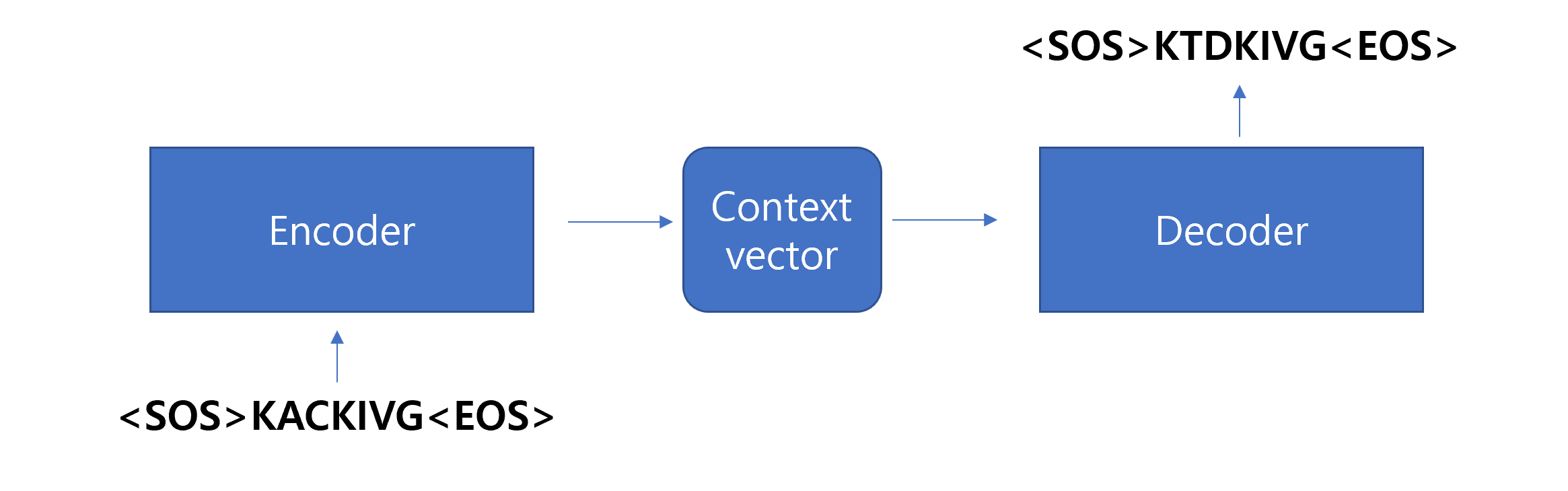
import numpy as np
import torch
from torch.utils.data import Dataset, DataLoader
class Seq2SeqDataset(Dataset):
def __init__(self, source_sequences, target_sequences):
self.source_sequences = source_sequences
self.target_sequences = target_sequences
def __len__(self):
return len(self.source_sequences)
def __getitem__(self, idx):
return self.source_sequences[idx], self.target_sequences[idx]
# Example amino acids
amino_acids = ["A", "R", "N", "D", "C", "Q", "E", "G", "H", "I", "L", "K", "M", "F", "P", "S", "T", "W", "Y", "V"]
# Generate source sequences
num_sequences = 100 # number of samples
sequence_length = 10
source_sequences = [
"".join(np.random.choice(amino_acids, size=sequence_length)) for _ in range(num_sequences)
]
# Transformation pattern for generating target sequences
def transform_to_target(sequence):
# Example pattern: Reverse the sequence and replace specific amino acids
mapping = {"A": "T", "R": "N", "N": "R", "D": "C", "C": "D"} # Custom substitution rules
transformed = [mapping.get(aa, aa) for aa in sequence] # substitution
return "".join(transformed)
# Create target sequences based on the pattern
target_sequences = [transform_to_target(seq) for seq in source_sequences]
# Build vocabulary
vocab = {aa: idx for idx, aa in enumerate(amino_acids)}
# include padding token, <pad>, start token <sos> and end token <eos>
vocab["<pad>"] = len(vocab)
vocab["<sos>"] = len(vocab)
vocab["<eos>"] = len(vocab)
vocab_size = len(vocab)
# Build idx2vocab
idx2vocab = {idx: aa for aa, idx in vocab.items()}
# Encode sequences into integer indices
def encode_sequence(sequence, vocab):
return [vocab[aa] for aa in sequence]
encoded_source_sequences = [encode_sequence(seq, vocab) for seq in source_sequences]
encoded_target_sequences = [encode_sequence(seq, vocab) for seq in target_sequences]
# Collate function for padding
# The collate_batch function handles these differences by padding shorter sequences so that
# all sequences in a batch have the same length.
def collate_batch(batch, vocab_size):
source_batch, target_batch = zip(*batch)
source_lengths = [len(seq) for seq in source_batch]
target_lengths = [len(seq) for seq in target_batch]
# Pad sequences
max_src_len = max(source_lengths)
max_tgt_len = max(target_lengths)
padded_src = torch.zeros(len(source_batch), max_src_len, dtype=torch.long)
padded_tgt = torch.zeros(len(target_batch), max_tgt_len, dtype=torch.long)
for i, seq in enumerate(source_batch):
padded_src[i, :len(seq)] = torch.tensor(seq, dtype=torch.long)
for i, seq in enumerate(target_batch):
padded_tgt[i, :len(seq)] = torch.tensor(seq, dtype=torch.long)
return padded_src, source_lengths, padded_tgt, target_lengths
# Create dataset and dataloader
# separate training and test data
from sklearn.model_selection import train_test_split
train_source, test_source, train_target, test_target = train_test_split(encoded_source_sequences, encoded_target_sequences, test_size=0.2)
train_dataset = Seq2SeqDataset(train_source, train_target)
train_dataloader = DataLoader(train_dataset, batch_size=4, shuffle=True, collate_fn=lambda x: collate_batch(x, vocab_size))
test_dataset = Seq2SeqDataset(test_source, test_target)
test_dataloader = DataLoader(test_dataset, batch_size=4, shuffle=False, collate_fn=lambda x: collate_batch(x, vocab_size))
# Example batch
for batch in train_dataloader:
src, src_len, tgt, tgt_len = batch
print("Source batch shape:", src.shape)
print("Source lengths:", src_len)
print("Target batch shape:", tgt.shape)
print("Target lengths:", tgt_len)
breakSource batch shape: torch.Size([4, 10])
Source lengths: [10, 10, 10, 10]
Target batch shape: torch.Size([4, 10])
Target lengths: [10, 10, 10, 10]