Model architecture (e.g. linear regression, classification, …, \(y=b_0 + b_1x\))
Data collection
Data preprocessing (e.g. normalization etc.)
Model fitting (finding \(b_0\) and \(b_1\))
Find the best model by repeating 2 and 5 (not including 3 and 4)
Hypothesis evaluation
Modeling for prediction (deep learning model)
Objectives
Model architecture (regression, classification, cnn, lstm, transformer, embeding models)
Data collection
Data preprocessing (e.g. encoding and embeding etc.)
Model fitting (forward, backward)
Find the best model by repeating 2, 4, 5
Deploy (Use for prediction)
Monitoring
3.2 Multiple regression
Multiple Regression is a type of supervised learning where the model assumes a linear relationship between the input features \(X\) and the target \(y\): \[
y = \beta_0 + \beta_1 x_1 + \beta_2 x_2 + \ldots + \beta_p x_p + \epsilon
\]
Where:
\(X = [x_1, x_2, \ldots, x_p]\) are the input features (gene \(x_i\) expresion value, \(y\) is target gene expression value)
\(\beta_0, \beta_1, \ldots, \beta_p\) are the model coefficients (parameters).
\(\epsilon\) is the error term.
3.3 Neural networks
A neural network with no hidden layers and a single output node is essentially a multiple regression model \[
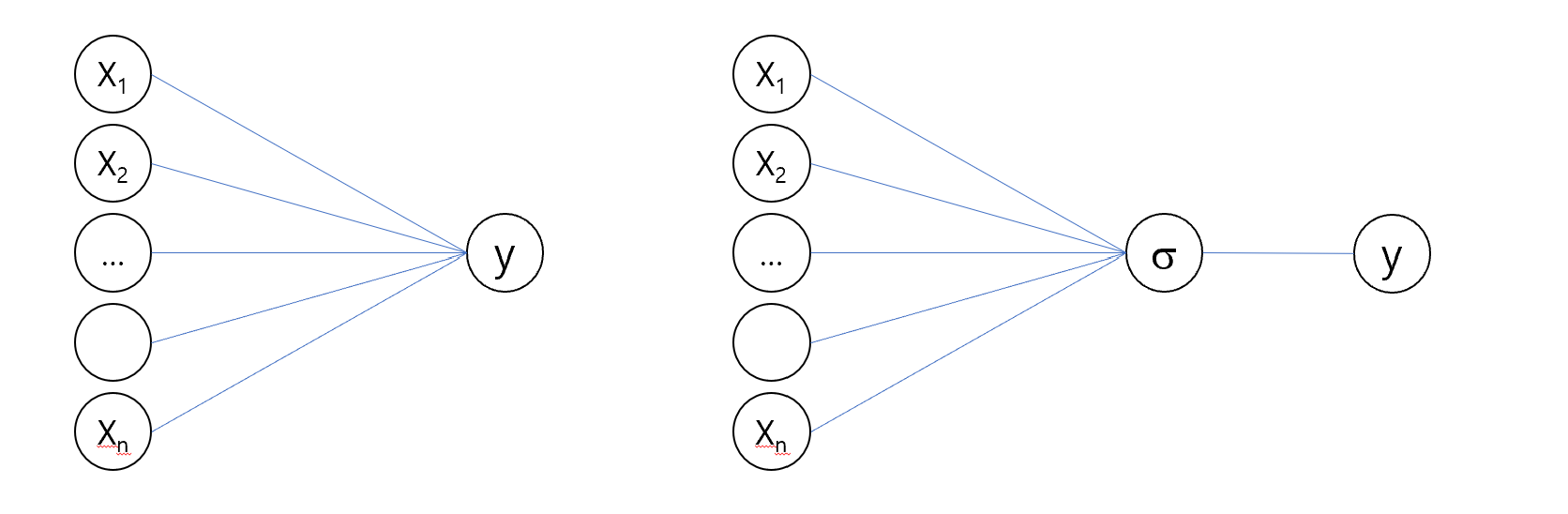
y = \sigma(W \cdot X + b)
\]
Where:
\(W\): Weight vector (equivalent to () in regression).
\(b\): Bias term (equivalent to (_0) in regression).
\(\sigma\): activation function
Multiple regression can be seen as a very simple neural network
3.3.1 Key Differences between linear regression and neural networks
Linear vs. non-linear: Neural Networks with hidden layers and non-linear activation functions (e.g., ReLU, sigmoid), they can model highly complex, non-linear relationships.
Interactions: Multiple Regression requires manual engineering of interaction terms (e.g., \(x_1 \times x_2\). But Neural Networks automatically learn interactions between features through layers of non-linear transformations.
Scale: linear regression is available with low-dimensional features while NN handle high-dimensional inputs, such as images or text.
3.3.2 Neural Networks Extension
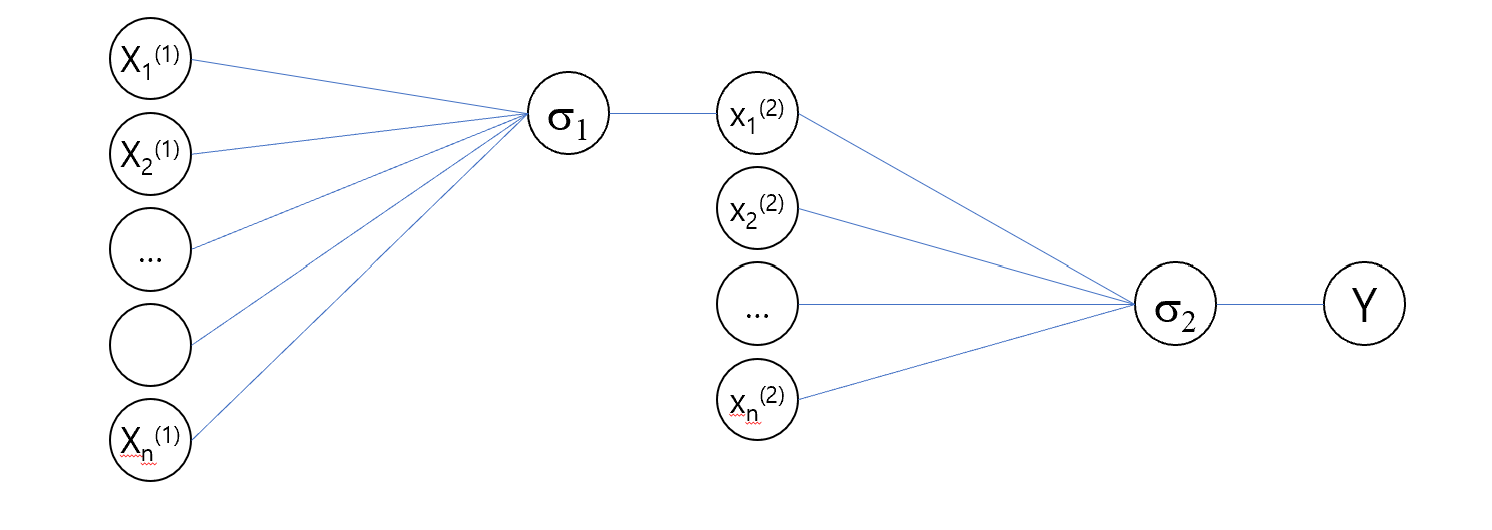
By introducing hidden layers and non-linear activation functions, neural networks extend regression to capture non-linear relationships: \[
y = \sigma(W_2 \cdot \sigma(W_1 \cdot X + b_1) + b_2)
\] where: - \(W_1\) and \(W_2\): Weight matrices for hidden and output layers. - \(b_1\) and \(b_2\): Bias terms. - \(\sigma\): Non-linear activation function (e.g., ReLU, sigmoid).
Deeper networks with multiple layers allow for hierarchical feature learning, capturing increasingly abstract patterns in data.
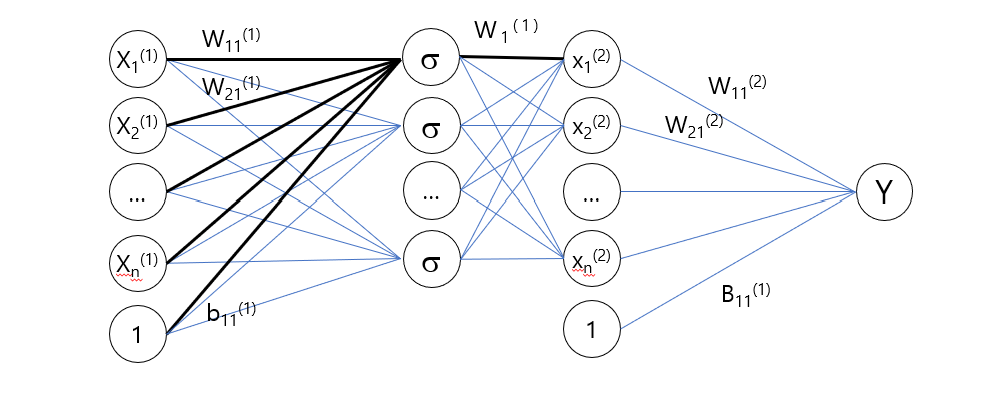
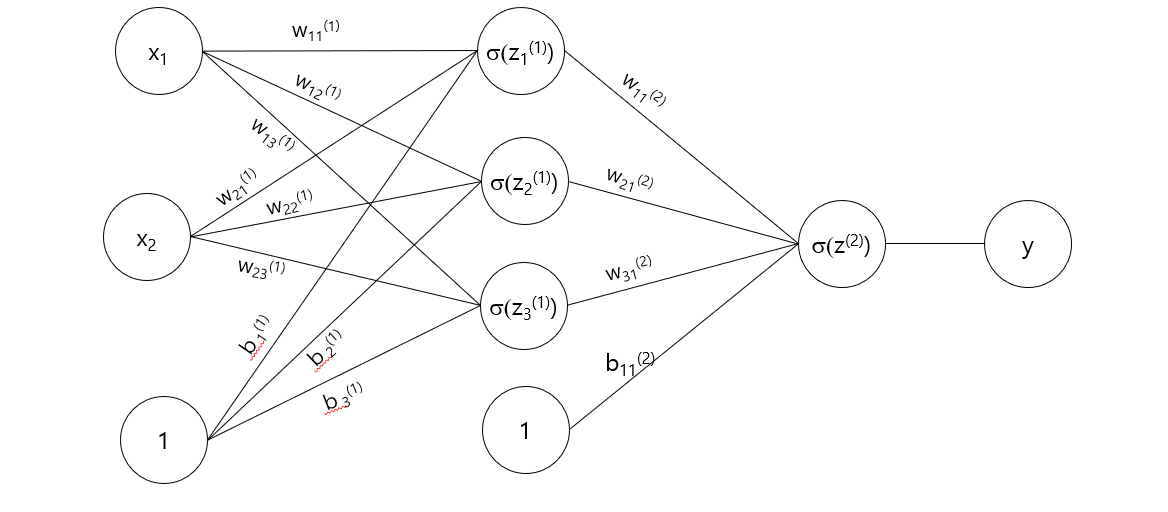
3.3.3 Architecture of neural networks
Neurons (Nodes): Basic units of a neural network that take inputs, perform a computation, and pass outputs
Layers:
Input Layer: The starting point where data is fed into the network
Hidden Layers: Intermediate layers between the input and output
Output Layer: The final layer that produces the result (classification, regression)
3.3.4 Weights and Biases:
Weights: Parameters that determine the strength. Adjusted during training
Biases: Additional parameters added to the input. It allows more flexibility
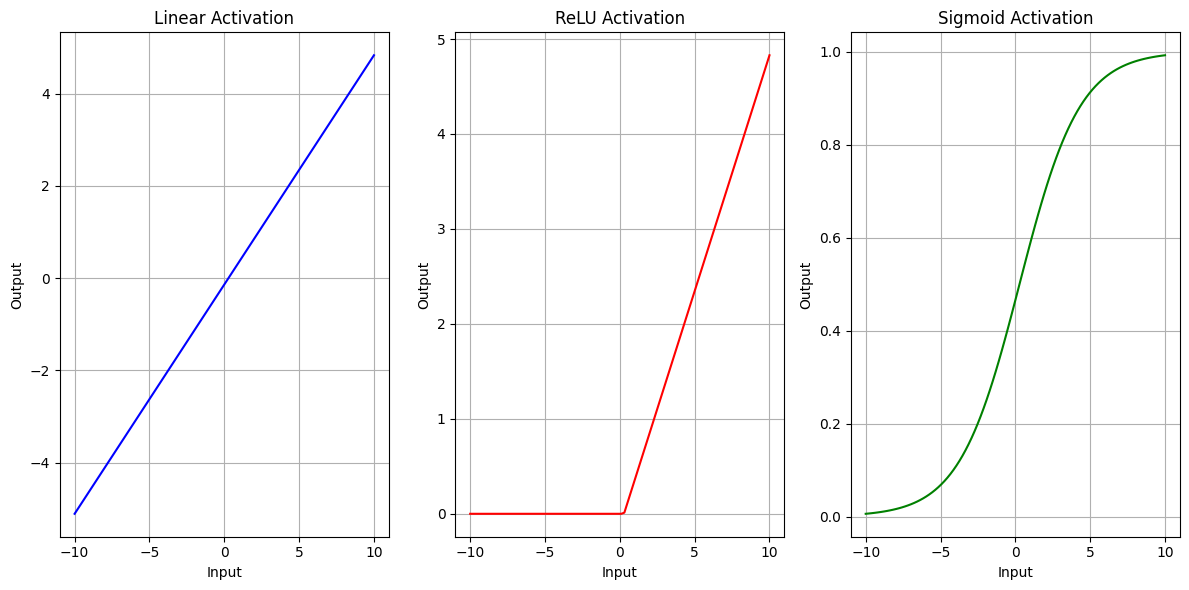
3.3.5 Activation Functions
Activation functions introduce non-linearity to the model, enabling it to learn complex patterns.
Common activation functions include:
ReLU (Rectified Linear Unit): $ f(x) = (0, x) $
Sigmoid: $ f(x) = $
Tanh: $ f(x) = $
import numpy as npimport matplotlib.pyplot as plt# Generate synthetic datanp.random.seed(42)X = np.linspace(-10, 10, 100).reshape(-1, 1) # Input: 100 points from -10 to 10weights = np.random.randn(1, 1) # Random weightsbias = np.random.randn(1) # Random bias# Linear transformationlinear_output = X @ weights + bias# Activation functionsdef identity(x):return x # Linear (no activation)def relu(x):return np.maximum(0, x) # ReLUdef sigmoid(x):return1/ (1+ np.exp(-x)) # Sigmoid# Apply activation functionsoutput_identity = identity(linear_output)output_relu = relu(linear_output)output_sigmoid = sigmoid(linear_output)# Plot resultsplt.figure(figsize=(12, 6))# Plot the input-output relationship for each activation functionplt.subplot(1, 3, 1)plt.plot(X, output_identity, label="Linear Activation (Identity)", color="blue")plt.title("Linear Activation")plt.xlabel("Input")plt.ylabel("Output")plt.grid(True)plt.subplot(1, 3, 2)plt.plot(X, output_relu, label="ReLU Activation", color="red")plt.title("ReLU Activation")plt.xlabel("Input")plt.ylabel("Output")plt.grid(True)plt.subplot(1, 3, 3)plt.plot(X, output_sigmoid, label="Sigmoid Activation", color="green")plt.title("Sigmoid Activation")plt.xlabel("Input")plt.ylabel("Output")plt.grid(True)plt.tight_layout()plt.show()
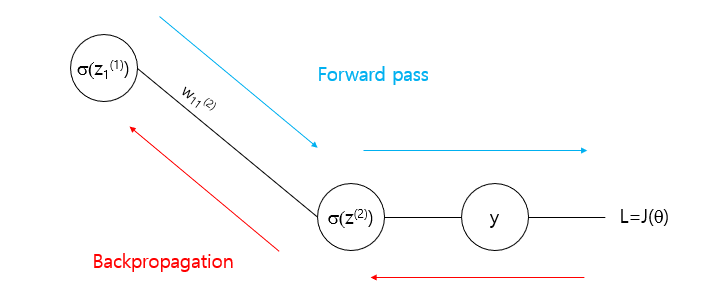
3.3.6 Forward Pass
The process of passing input data through the network, layer by layer, to produce an output.
Each neuron computes a weighted sum of its inputs, adds a bias, and passes the result through an activation function.
This involves applying a linear transformation.
3.3.6.1 (Example) of Forward Pass and Loss Function
Let’s consider a simple neural network with: - 1 Input Layer: 2 input nodes. - 1 Hidden Layer: 3 nodes with ReLU (Rectified Linear Unit) activation. - 1 Output Layer: 1 node with sigmoid activation.
The forward pass computes: 1. Input to Hidden Layer: \[
Z^{(1)} = X W^{(1)} + b^{(1)} \\
\]
A measure of how well the neural network’s predictions match the actual data. Common loss functions include Mean Squared Error (MSE) for regression and Cross-Entropy Loss for classification.
\[
L = \frac{1}{n} || y - \hat{y} ||^2 = \frac{1}{n}\sum(y_i-\hat{y}_i)^2
\]
np.mean((y - y_hat)**2)
0.22009897381259744
3.3.8 Backpropagation and Training
Backpropagation: The process of adjusting weights and biases based on the loss. It uses gradients computed by the chain rule to update these parameters through gradient descent or other optimization algorithms.
Optimization Algorithm: Techniques like Stochastic Gradient Descent (SGD) or Adam adjust the model parameters to minimize the loss.
3.3.8.1 Chain Rule
Derivative of a composite function \[
z = f(g(x))
\]
PyTorch is an open-source deep learning framework developed by Facebook’s AI Research lab (FAIR). It is widely used in research and industry due to its dynamic computation graph and ease of use.
PyTorch Ecosystem Overview:
torch: The core library for tensor operations and automatic differentiation.
torch.nn: A sub-library used to build and train neural network models.
torch.optim: Tools for optimization algorithms (e.g., SGD, Adam).
torchvision: Provides datasets, pre-trained models, and image transformations.
Tensors
Tensors are the primary data structures in PyTorch, analogous to NumPy arrays but with added capabilities such as the ability to run on GPUs for faster computation.
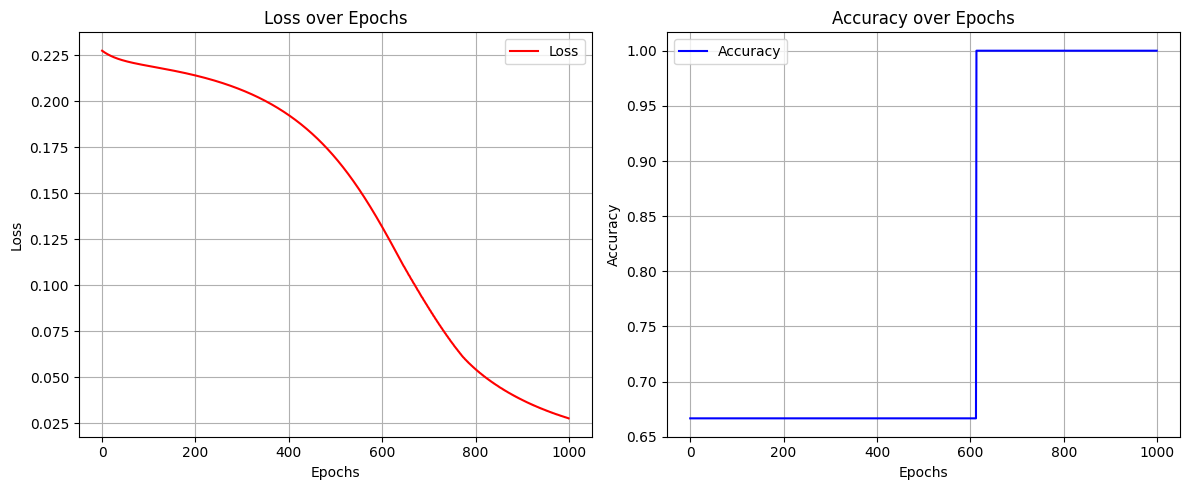
import torchimport torch.nn as nnimport torch.optim as optimimport matplotlib.pyplot as plt# Input data and true labelsX = torch.tensor([[0.5, 0.2], [0.1, 0.4], [0.6, 0.9]], dtype=torch.float32) # Shape (3 samples, 2 features)y = torch.tensor([[1], [0], [1]], dtype=torch.float32) # True labels (Shape: 3x1)# Define the neural networkclass SimpleNN(nn.Module):def__init__(self):super(SimpleNN, self).__init__()# Define layersself.hidden = nn.Linear(2, 3) # Input to hidden layer (2 inputs, 3 hidden nodes)self.output = nn.Linear(3, 1) # Hidden to output layer (3 hidden nodes, 1 output)def forward(self, x):# Forward pass: Input -> Hidden Layer -> Output Layer x = torch.relu(self.hidden(x)) # ReLU activation for hidden layer x = torch.sigmoid(self.output(x)) # Sigmoid activation for output layerreturn x# Initialize the networkmodel = SimpleNN()# Loss function and optimizercriterion = nn.MSELoss() # Mean Squared Error Lossoptimizer = optim.SGD(model.parameters(), lr=0.1) # Stochastic Gradient Descent optimizer# Training parametersepochs =1000# Containers to store loss and accuracy for each epochloss_history = []accuracy_history = []# Training loopfor epoch inrange(epochs):# Forward pass outputs = model(X) # Predicted outputs loss = criterion(outputs, y) # Compute loss# Compute accuracy predicted = (outputs >=0.5).float() # Threshold at 0.5 for binary classification accuracy = (predicted == y).sum().item() / y.size(0)# Backpropagation optimizer.zero_grad() # Clear previous gradients loss.backward() # Compute gradients optimizer.step() # Update weights# Record loss and accuracy loss_history.append(loss.item()) accuracy_history.append(accuracy)# Print loss every 100 epochsif epoch %100==0:print(f"Epoch {epoch}, Loss: {loss.item():.4f}")# Final predictionswith torch.no_grad(): # No need to compute gradients during inference final_outputs = model(X)print("\nFinal Predictions:")print(final_outputs)# Plot the loss and accuracy over epochsplt.figure(figsize=(12, 5))# Loss plotplt.subplot(1, 2, 1)plt.plot(range(epochs), loss_history, label="Loss", color="red")plt.xlabel("Epochs")plt.ylabel("Loss")plt.title("Loss over Epochs")plt.grid(True)plt.legend()# Accuracy plotplt.subplot(1, 2, 2)plt.plot(range(epochs), accuracy_history, label="Accuracy", color="blue")plt.xlabel("Epochs")plt.ylabel("Accuracy")plt.title("Accuracy over Epochs")plt.grid(True)plt.legend()plt.tight_layout()plt.show()