Chapter 4 R programming basics II
4.1 A script in R
R 프로그래밍을 통해서 사용자가 원하는 기능을 수행하는 방법은 다음과 같이 스크립트를 만들어서 실행하는 것 입니다. 일반적으로 R을 이용한 스크립트 명령을 어떻게 실행하는지 알아보겠습니다. 다음 예제는 입력 값들의 평균을 계산해서 출력해 주는 스크립트 명령입니다. R base 패키지에서 기본으로 제공되는 mean()이라는 함수가 있지만 사용하지 않고 sum()과 length() 함수를 사용했습니다.
numbers <- c(0.452, 1.474, 0.22, 0.545, 1.205, 3.55)
cat("Input numbers are", numbers, "\n")
numbers_mean <- sum(numbers)/length(numbers)
out <- paste("The average is ", numbers_mean, ".\n", sep="")
cat(out)상황에 따라 다르긴 하지만 보통 위 스크립트를 실행할 때 R 파일을 하나 만들고 source()라는 함수를 사용해서 파일 전체를 한번에 읽어들이고 실행을 시킵니다. 위 코드를 myscript.R 이라는 새로운 R 파일을 하나 만들고 저장 후 다음과 같이 실행할 수 있습니다. 참고로 위 파일은 현재 working directory와 같은 위치에 저장해야 합니다.
그러나 위와 같은 식으로 실행할 경우 다음 몇 가지 문제가 있습니다. 하나는 입력 값이 바뀔 때마나 파일을 열어 바뀐 값을 저장해 줄 필요가 있습니다. 결과 값에 대해서 다른 처리를 하고 싶을 경우 또한 파일을 직접 수정해 주어야 합니다. 또한 모든 변수들이 전역변수로 사용되어 코드가 복잡해질 경우 변수간 간섭이 생길 가능성이 높습니다.
4.2 Functions
함수를 사용하면 위와같은 문제를 극복할 수 있습니다. 함수(Function)는 다음과 같은 포멧으로 구현할 수 있습니다.
예를 들어 다음과 같은 my_sine 함수를 만들 수 있으며 parameter (매개변수)는 x이고 y는 반환값을 저장하는 지역변수 입니다.
만들어진 함수는 다음과 같이 사용할 수 있습니다. 만들어진 함수는 처음에 한 번 실행해 주어 실행중인 R session에 등록한 후 사용할 수 있습니다. 여기서 함수로 전달되는 값 pi는 argument (전달인자) 라고 합니다. 전달인자는 함수에서 정의된 매개변수의 갯수와 같은 수의 전달인자를 입력해 주어야 합니다.
- Terminology
- function name:
my_sine - parameter:
x - argument:
pi - return value:
y
- function name:
이제 위 스크립트에서 사용된 코드를 함수로 바꿔봅니다. numbers (전달인자)를 받는 매개변수를 x로 하고 함수 이름은 mymean 이고 평균값 (numbers_mean)을 반환하는 합수입니다.
numbers <- c(0.452, 1.474, 0.22, 0.545, 1.205, 3.55)
mymean <- function(x){
cat("Input numbers are", x, "\n")
numbers_mean <- sum(x)/length(x)
out <- paste("The average is ", numbers_mean, ".\n", sep="")
cat(out)
return(numbers_mean)
}
retval <- mymean(numbers)
cat(retval)myscript.R이라는 파일을 열고 작성된 스크립트에 더해서 아래처럼 함수 코드를 만들 경우 source() 함수로 함수를 세션으로 읽어오고 바로 사용할 수 있습니다. 위와 같이 함수를 만들 경우 입력 값을 언제든 바꿔서 사용할 수 있고 반환값에 대한 추가적인 연산도 쉽게 수행 할 수 있습니다.
4.2.1 Exercise 4-1
mysd라는 이름의 (표본)표준편차를 구하는 함수를myscript.R파일에 구현하시오 (sd()함수 사용 불가, 다음 표준편차 공식 이용)
\[ \sigma = \sqrt{\frac{\sum(x-mean(x))^2}{length(x)-1}} \]
코드는 아래와 같음
1부터 100까지의 값을
x에 저장하고 mysd 함수를 사용해서 표준편차를 구하시오앞서 작성한
mymean함수와mysd함수를 같이 사용하여x를 표준화 하고y로 저장하시오. 표준화 공식은 다음과 같음
\[ y = \frac{x - mean(x)}{sd(x)} \]
x와y를 갖는z라는 이름의data.frame을 생성하시오
다음 코드를 보면 전역변수 x, y는 지역변수 x, y와 독립적으로 사용됨을 알 수 있습니다.
my_half <- function(x){
y <- x/2
cat("local variable x:", x, "\n")
cat("local variable y:", y, "\n")
return(y)
}
y <- 100
x <- 20
cat("Global variable x:", x, "\n")
cat("Global variable y:", y, "\n")
my_half(5)log, sin등의 함수들은 Built-in function으로 같은 이름의 함수를 만들지 않도록 주의합니다.
4.3 Vectorized functions
초기에 R이 다른 프로그래밍 언어에 비해서 경쟁력을 갖는 이유 중 하나가 바로 이 벡터 연산 기능 이였습니다. vector 변수에 들어있는 각 원소들에 대해서 특정 함수나 연산을 적용하고 싶을 경우 전통 방식의 C나 Java등의 언어에서는 원소의 개수만큼 반복문을 돌면서 원하는 작업을 수행 했습니다. 그러나 R의 벡터 연산 기능은 별도의 반복문 없이 vector 안에 있는 원소들에 대한 함수 실행 또는 연산을 수행할 수 있습니다.
x <- c(10, 20, 30)
x + x
sqrt(x)
sin(x)
log(x)
x-mean(x)
length(x)
test_scores <- c(Alice = 87, Bob = 72, James= 99)
names(test_scores)4.3.1 Exercise 4-2
다음은 한 다이어트 프로그램의 수행 전 후의 다섯 명의 몸무게이다.
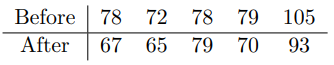
각각을 before 와 after 이름의 변수에 저장 후 몸무게 값의 변화량을 계산하여 diff 라는 변수에 저장하고 diff에 저장된 값들의 평균을 구하시오
my_mean 이라는 이름의 함수로 평균을 구하는 코드를 작성 하시오 (빌트인 함수 사용하지 않음)
- 함수이름: my_mean
- parameter: x
- return 값: y
- (x[1]+x[2]+x[3]+x[4]+x[5])/5
- 빌트인 함수 sum()과 length()를 이용해 동일한 기능을 하는 함수를 작성하시오
- 함수이름 my_mean2
- sum(), length() 사용
4.3.2 Exercise 4-3
다음 네 학생이 있으며 “John”,“James”,“Sara”, “Lilly” 각 나이는 21, 55, 23, 53 이다. ages 라는 변수를 생성하고 각 나이를 저장한 후 who라는 이름의 함수를 만들어서 50살 이상인 사람의 이름을 출력하는 함수를 만드시오.
- ages라는 변수에 나이 저장, c() 함수 이용, vector 형태 저장
- names() 함수 이용해서 각 ages 벡터의 각 요소에 이름 붙이기
- which() 함수 사용해서 나이가 50보다 큰 인덱스 찾고 해당 인덱스 값 출력 하기
- ages를 메개변수로 받아서 나이가 50보다 큰 인덱스 찾고 해당 인덱스의 값을 반환해 주는 who 함수 만들고 사용
4.4 if statements
R에서의 제어문의 사용은 다른 프로그래밍 언어와 거의 유사합니다. 먼저 if 는 다음과 같은 형식으로 사용되며 () 안에 특정 조건 판단을 위한 표현이 들어갑니다.
특히 condition은 하나의 원소에 대한 조건 판단문으로 T 또는 F 값 하나만을 반환하는 문장이어야 합니다. 위 코드는 만약 condition 조건이 True 이면 expr_1를 실행하고 False이면 expr_2를 실행하라는 명령입니다. condition 안에서 사용되는 비교 연산자들은 다음과 같습니다.

x <- 2
if(x%%2 == 1){
cat("Odd")
}else{
cat("Even")
}
x <- 5
if(x > 0 & x < 4){
print("Positive number less than four")
}
if(x > 0) print("Positive number")
x <- -5
if(x > 0){
print("Non-negative number")
} else if(x <= 0 & x > -5){
print("Negative number greater than -5")
} else {
print("Negative number less than -5")
}
if(x > 0)
print("Non-negative number")
else
print("Negative number")4.4.1 Exercise 4-4
1부터 100까지 수 중 랜덤하게 1 개의 값을 골라 n 변수에 저장하고 다시 1부터 100까지 랜덤하게 n개의 수를 중복을 허용해서 골라 x 변수에 저장 하시오 (랜덤 생성:
sample()함수 사용)다음은 median (중간값)을 구하는 공식이며 x의 길이가 (n이) 홀수일 경우와 짝수일 경우에 따라서 다른 공식이 사용된다. 다음 공식과 코드를 이용하여 mymedian 이라는 이름의 함수를 만들고 입력 값들의 중간값을 구해서 반환하는 함수를 만드시오. (
%%나머지 연산,if문 사용, 아래 중간값 코드 참고)
\[ median(X) = \begin{cases} \frac{1}{2} X[\frac{n}{2}] + \frac{1}{2} X[1+\frac{n}{2}] & \mbox{if } n \mbox{ is even} \\ X[\frac{n+1}{2}] & \mbox{if } n \mbox{ is odd} \end{cases} \]
4.5 for, while, repeat
for 문은 반복적으로 특정 코드를 실행하고자 할 때 사용됩니다. 다음과 같은 형식으로 사용할 수 있습니다. var는 반복을 돌 때마다 바뀌는 변수로 {} 안에서 사용되는 지역 변수 입니다. seq는 vector 형식의 변수로 반복을 돌 때마다 순차적으로 var에 저장되는 값들 입니다.
for(var in seq){
expression
}
x <- 1:10
for(i in x){
cat(i, "\n")
flush.console()
}
sum_of_i <- 0
for(i in 1:10){
sum_of_i <- sum_of_i + i
cat(i, " ", sum_of_i, "\n");flush.console()
}while문도 for문과 같이 반복적으로 특정 코드를 수행하고자 할 때 사용합니다. 사용하는 문법은 다음과 같으며 cond는 True 또는 False 로 반환되는 조건문을 넣고 True 일 경우 계속해서 반복하면서 expressions를 수행하며 이 반복은 cond가 False로 될 때 까지 계속됩니다.
while문을 사용할 경우 다음과 같이 indicator라 불리우는 변수를 하나 정해서 반복 할 때마다 값이 바뀌도록 해 주어야 합니다. 그렇지 않으면 무한 루프를 돌게 되는 문제가 발생합니다.
repeat 명령은 조건 없이 블럭 안에 있는 코드를 무조건 반복하라는 명령 입니다. 따라서 블럭 중간에 멈추기 위한 코드가 필요하고 이 명령이 break 입니다.
4.6 Avoiding Loops
R에서는 가능하면 loop문을 사용하지 않는 것이 좋습니다. 이는 다른 언어들 보다 반복문이 느리게 수행된다는 이유 때문이기도 합니다. 그러나 R에서는 반복문을 수행하는 것 보다 훨씬 더 빠르게 반복문을 수행 한 것과 같은 결과를 얻을 수 있는 다양한 방법들이 제공되고 있습니다. 차차 그런 기법들에 대한 학습을 진행하도록 하겠습니다.
4.7 Object Oriented Programming (Advanced)
OOP는 객체지향 프로그래밍 이라고 합니다. OOP를 이용해서 프로그래밍으로 풀고자 하는 문제를 좀 더 명확하게 개념을 수립하고 복잡한 코드를 명료하게 만들 수 있습니다. 그런데 R에서 OOP는 다른 언어보다는 좀 더 어려운 개념적인 이해가 필요합니다. S3, S4, 그리고 Reference class 가 있으며 S3, S4는 Generic function을 이용하며 다른 언어에서 사용하는 OOP 개념과는 다릅니다. Reference class는 다른 언어에서 사용하는 OOP 개념과 유사하며 R6 패키지를 이용해서 사용할 수 있습니다.
4.8 Usuful functions II
#match(), %in%, intersect()
x <- 1:10
y <- 5:15
match(x, y)
x %in% y
intersect(x, y)
#unique()
unique(c(x, y))
#substr()
x <- "Factors, raw vectors, and lists, are converted"
substr(x, 1, 6)
#grep()
grep("raw", x)
#grepl()
grepl("raw", x)
if(grepl("raw", x)){
cat("I found raw!")
}
x <- paste(LETTERS, 1:100, sep="")
grep("A", x)
x[grep("A", x)]
grepl("A", x)
r <- grepl("A", x)
if(r){
cat("Yes, I found A")
}else{
cat("No A")
}
#strsplit()
x <- c("Factors, raw vectors, and lists, are converted", "vectors, or for, strings with")
y <- strsplit(x, split=", ")
#unlist()
unlist(y)
y <- strsplit(x, split="")
ychar <- unlist(y)
ycount <- table(y2)
ycount_sort <- sort(ycount)
ycount_sort <- sort(ycount, decreasing = T)
ycount_top <- ycount_sort[1:5]
ycount_top_char <- names(ycount_top)
#toupper(), tolower()
toupper(ycount_top_char)4.8.1 Exercise 4-5
built-in 데이터셋 중 state.abb 은 미국의 50개 주에대한 축약어임.
이 중 문자 A 가 들어가는 주를 뽑아 x에 저장 하시오 (
grep또는grepl사용)state.abb 중 위 x에 저장된 이름들을 빼고 y에 저장 하시오 (
match()또는%in%사용)state.abb에 사용된 알파벳의 갯수를 구하고 가장 많이 쓰인 알파벳을 구하시오 (
strsplit(),table()등 사용)
4.9 File read and write
텍스트 파일의 경우 아래와 같이 csv 또는 txt 파일로 저장하여 메모장으로 열어 확인할 수 있으며 읽어올 경우 구분자 (sep 파라메터) 나 header를 (header 파라메터) 읽을지 읽지 않을지 등을 옵션으로 지정할 수 있습니다.
x <- c(1,2,3,4)
y <- c(5,6,7,8)
xy<-data.frame(x=x, y=y)
write.table(xy, file="table_write.txt")
write.table(xy, file="table_write.txt", quote=F)
write.table(xy, file="table_write.txt", quote=F, row.names=F)
write.table(xy, file="table_write.txt", quote=F, row.names=F, sep=",")
write.table(xy, file="table_write.csv", quote=F, row.names=F, sep=",")
mydata<-read.table(file="table_write.csv")
mydata<-read.table(file="table_write.csv", sep=",")
mydata<-read.table(file="table_write.csv", sep=",", header=T)
plot(mydata$x, mydata$z)4.9.1 Exercise 4-6
iris 데이터셋을 iris.csv에 ,를 구분 기호로 저장하고 myiris 라는 변수로 다시 읽어 들이시오
4.10 Excel file read and data plotting
엑셀파일은 readxl 이라는 R 패키지를 활용하여 읽거나 쓸 수 있습니다.
실습 파일은 형광 세포를 배양하여 형광리더기를 이용해 얻어진 실제 데이터이며 Exp_data.xls 에서 다운로드 받을 수 있습니다. read_excel 함수를 이용하여 파일의 내용을 읽어오면 기본 자료형이 tibble 입니다. tibble은 최근 많이 쓰이는 R object로 data.frame과 유사하나 입력값의 type, name, rowname을 임으로 바꿀 수 없다는 점이 다릅니다.
엑셀파일에는 두 종류의 (OD600nm, fluorescence) 데이터가 저장되어 있습니다. 첫 번째 sheet에는 다음처럼 wide형 데이터가 저장되어 있습니다 (참고로 wide형 데이터는 일반적인 data.frame 형태의 데이터로 column은 변수, row는 샘플이 저장된 형태로 새로운 변수가 추가 되면 column 오른쪽에 붙어 wide하게 확장되는 것을 말합니다. long 형 데이터는 추후 강의에서 설명 드리겠습니다).
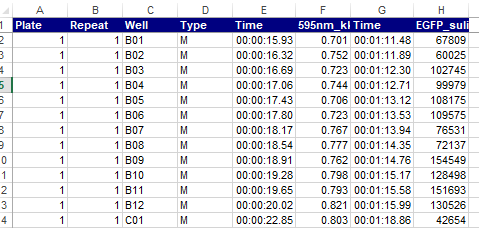
str 함수를 이용해서 데이터의 구조를 보면 8개의 변수가 있고 각 변수의 이름과 값의 타입 (mode of storage type) 그리고 실제 데이터들의 일부를 보여 줍니다. 이제 관심있는 변수만 뽑아서 가공을 해보겠습니다. 관심있는 변수는 594nm 으로 시작하는 OD 데이터와 EGFP로 시작하는 형광 데이터 그리고 well plate의 위치에 대한 label이 되겠습니다.
str(mydata)
mydf <- data.frame(well=mydata$Well, od=mydata$`595nm_kk (A)`, gfp=mydata$`EGFP_sulim (Counts)`)
head(mydf)아래 그림은 96 well plate의 각 well 마다 해당되는 위치와 label 값을 보여줍니다. 간단히 데이터를 설명하면 각 컬럼은 다른 종류의 cell 이고 row에 특정 화학물질의 농도별 측정 값을 나타냅니다. (1, 2), (3, 4), (5, 6), (7, 8), (9, 10), (11, 12) 각 pair는 같은 세포이고 반복 측정을 나타냅니다. 즉, 1과 2는 같은 종류의 세포이지만 반복을 2회 수행 한 것 입니다.
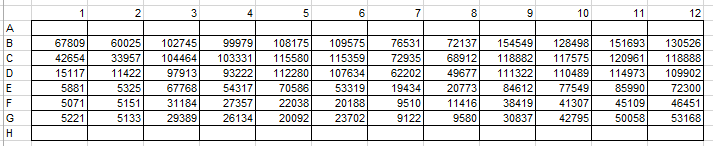
보통 데이터가 주어져 있을 때 가장 먼저 하는 일은 눈으로 직접 데이터 값을 보는 것 입니다. excel 파일을 열었을 경우 위 그림과 같은 형태의 값을 보고 대략적으로 세포별로 농도별로 값이 다르게 측정된 것을 확인합니다. 데이터 분석에서 그 다음 하는 일은 그래프 등을 통해서 raw데이터의 요약된 정보를 한 눈에 확인하는 작업 입니다. 이 후 데이터를 가공하거나 분석을 통해서 원하는 정보를 뽑아냅니다. 지금은 간단히 raw 데이터를 눈으로 확인하는 작업을 해 보겠습니다. 위 그림의 데이터를 그래프로 그릴 경우 가장 쉽게 생각할 수 있는 그림은 세포별 농도를 막대그래프로 그려보는 것 입니다.
가장 쉽게 1번 세포의 첫 번째 반복에 대해서 농도 B부터 G까지를 그리기 위해 해당하는 값을 뽑아서 데이터 세트를 만들어 봅니다. 먼저 well 이름을 이용해서 해당 값을 추출합니다.
mydf$well
class(mydf$well)
well_labels <- as.character(mydf$well)
strsplit(well_labels, split="")
well_concentration <- substr(well_labels, 1, 1)
cell_number <- substr(well_labels, 2, 3)
mydf2 <- data.frame(well_concentration, cell_number, mydf$od, mydf$gfp)
str(mydf2)
mydf2 <- data.frame(well_concentration, cell_number, mydf$od, mydf$gfp, stringsAsFactors = F)
str(mydf2)
mydf2$cell_number=="01"
idx <- mydf2$cell_number=="01"
mydf2_01 <- mydf2[idx,]
mydf2_01$mydf.gfp
plot(mydf2_01$mydf.gfp)
barplot(mydf2_01$mydf.gfp)
barplot(mydf2_01$mydf.gfp, names.arg = mydf2_01$well_concentration)그런데 위 데이터는 반복이 있는 데이터 입니다. 즉 반복 측정 값의 평균과 표준편차를 구해서 에러바와 같이 그려 주는 것이 보통 입니다. 1, 2 샘플에 대해서 농도별 평균과 표준편차를 구해봅니다. mydf2에서 1, 2 샘플만을 뽑고 작업을 시작 합니다.
seli1 <- which(mydf2$cell_number=="01")
sample1 <- mydf2[seli1,]
seli2 <- which(mydf2$cell_number=="02")
sample2 <- mydf2[seli2,]
sample_means <- (sample1$mydf.gfp + sample2$mydf.gfp)/2
sample_std <- sqrt(((sample1$mydf.gfp-sample_means)^2+(sample2$mydf.gfp-sample_means)^2)/(2-1))
sd(c(sample1$mydf.gfp[1], sample2$mydf.gfp[1]))
sample1df <- data.frame(conc=sample1$well_concentration, sample_means, sample_std)
sample1dfbarplot(sample1df$sample_means, names.arg=sample1df$conc, ylim=c(0, 80000))
arrows(0.7, sample_means[1], 0.7, sample_means[1]+sample_std[1], length=0.1, angle=90)
arrows(0.7, sample_means[1], 0.7, sample_means[1]-sample_std[1], length=0.1, angle=90)
lab <- paste("SD:", round(sample_means[1]+sample_std[1],1))
text(0.5, sample_means[1]+sample_std[1]*2, labels = lab)4.10.1 Exercise 4-7 barplot with error bars
앞서 그려본 막대그래프의 B, C, D, E, F, G 모두에 에러바를 넣으시오 (for 문 사용)
지금까지는 첫 번째 컬럼과 두 번째 컬럼의 데이터만을 읽어와서 그래프를 그려 보았습니다. 그러나 위 코드와 같은 방식으로 모든 데이터를 읽어오는 것은 비효율적입니다. 다음 강좌에서는 이러한 데이터를 좀 더 효율적으로 가공하는 방법과 R에서 제공하는 기본 그래프 함수에 대한 내용을 소개하도록 하겠습니다.

이 저작물은 크리에이티브 커먼즈 저작자표시-비영리-변경금지 4.0 국제 라이선스에 따라 이용할 수 있습니다.